|
Hi, I am Sucheng Ren (任苏成), a Computer Science Ph.D. student at Johns Hopkins University, where I am fortunate to be advised by Professor Alan Yuille and Prof. Cihang Xie. I received my B.S. and M.S. degree in Computer Science from South China University of Technology advised by Prof. Shengfeng He. Previously, I spent great time at Bytedance Seed, Microsoft Research Asia (MSRA), Tsinghua University and National University of Singapore. My research lies at the Diffusion/Autoregressive based Generative Model and Multimodal Learning. |

|
|
|
|
|
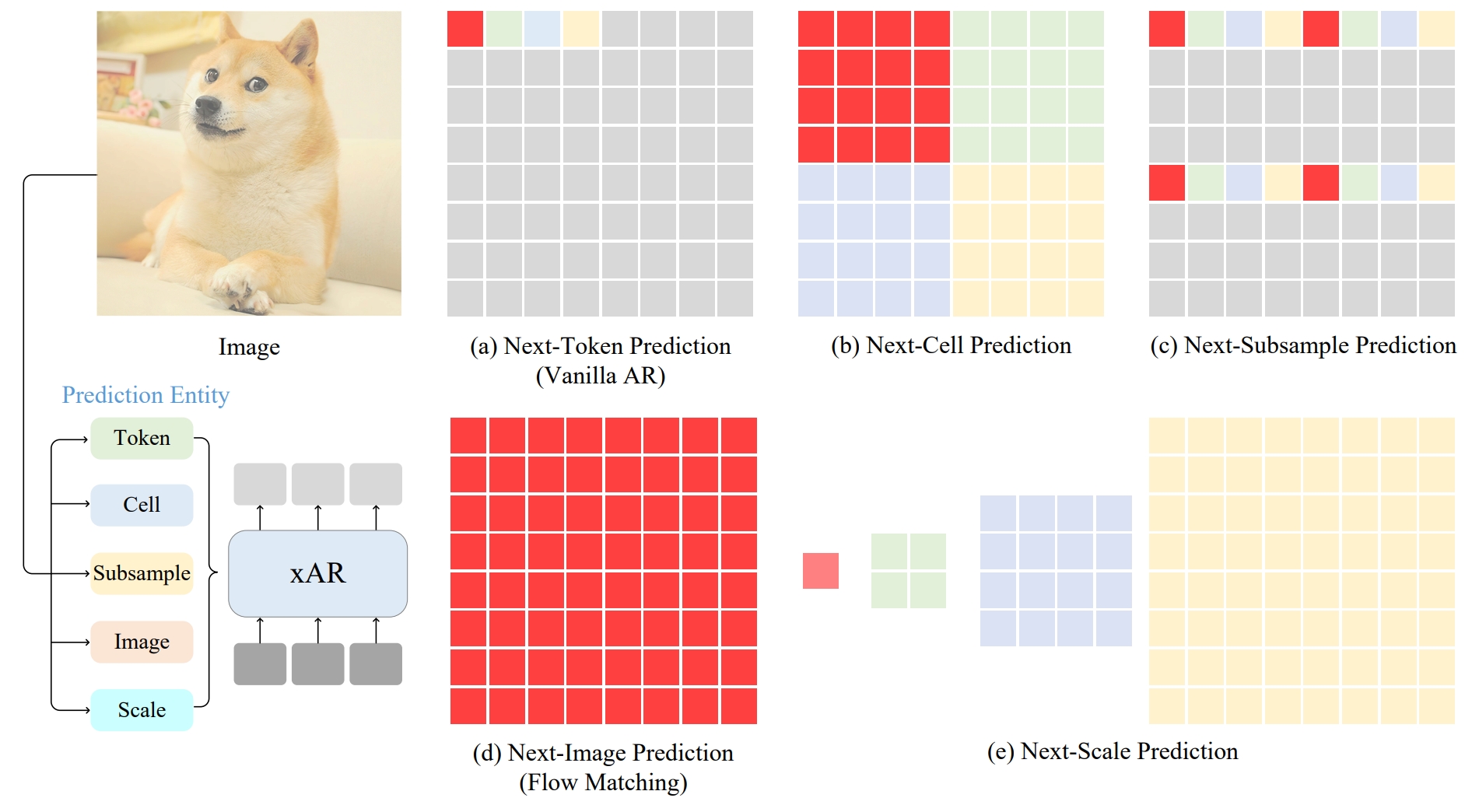 |
Sucheng Ren, Qihang Yu, Ju He, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen International Conference on Conputer Vision (ICCV), 2025 [paper] [code] [bibtex] We generalize next token prediction to next X prediction. |
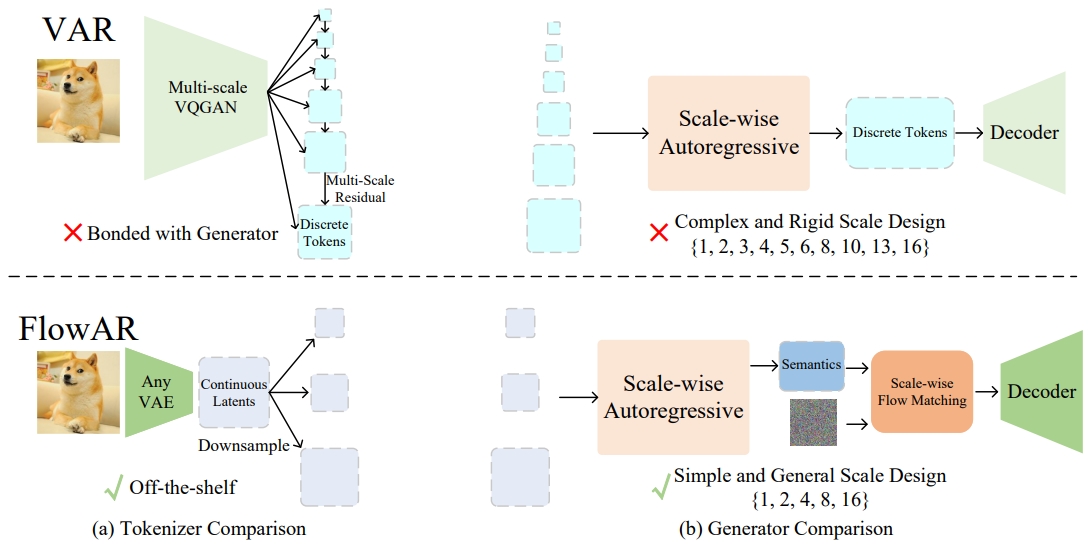 |
Sucheng Ren, Qihang Yu, Ju He, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen International Conference on Machine Learning (ICML), 2025 [paper] [code] [bibtex] We generalize next scale prediction to simplest scale design and make it compatible with any VAE. |
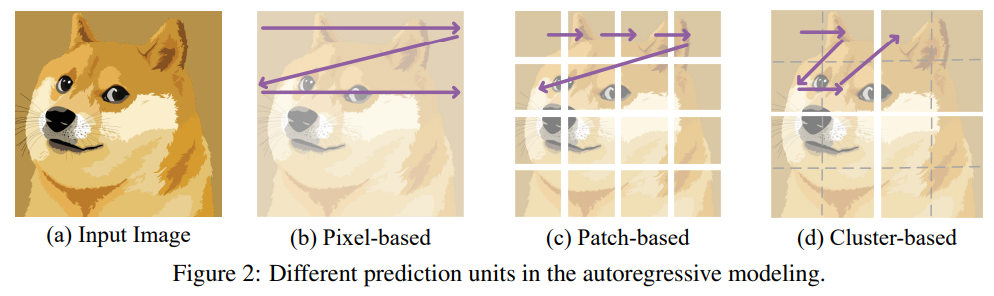 |
Sucheng Ren, Xianhang Li, Haoqin Tu, Feng Wang, Fangxun Shu, Lei Zhang, Jieru Mei, Linjie Yang, Peng Wang, Heng Wang, Alan Yuille, Cihang Xie International Conference on Learning Representation (ICLR), 2025 [paper] [code] [bibtex] We are the first to pretrain Mamba in vision with Cluster-based autoregressive modeling |
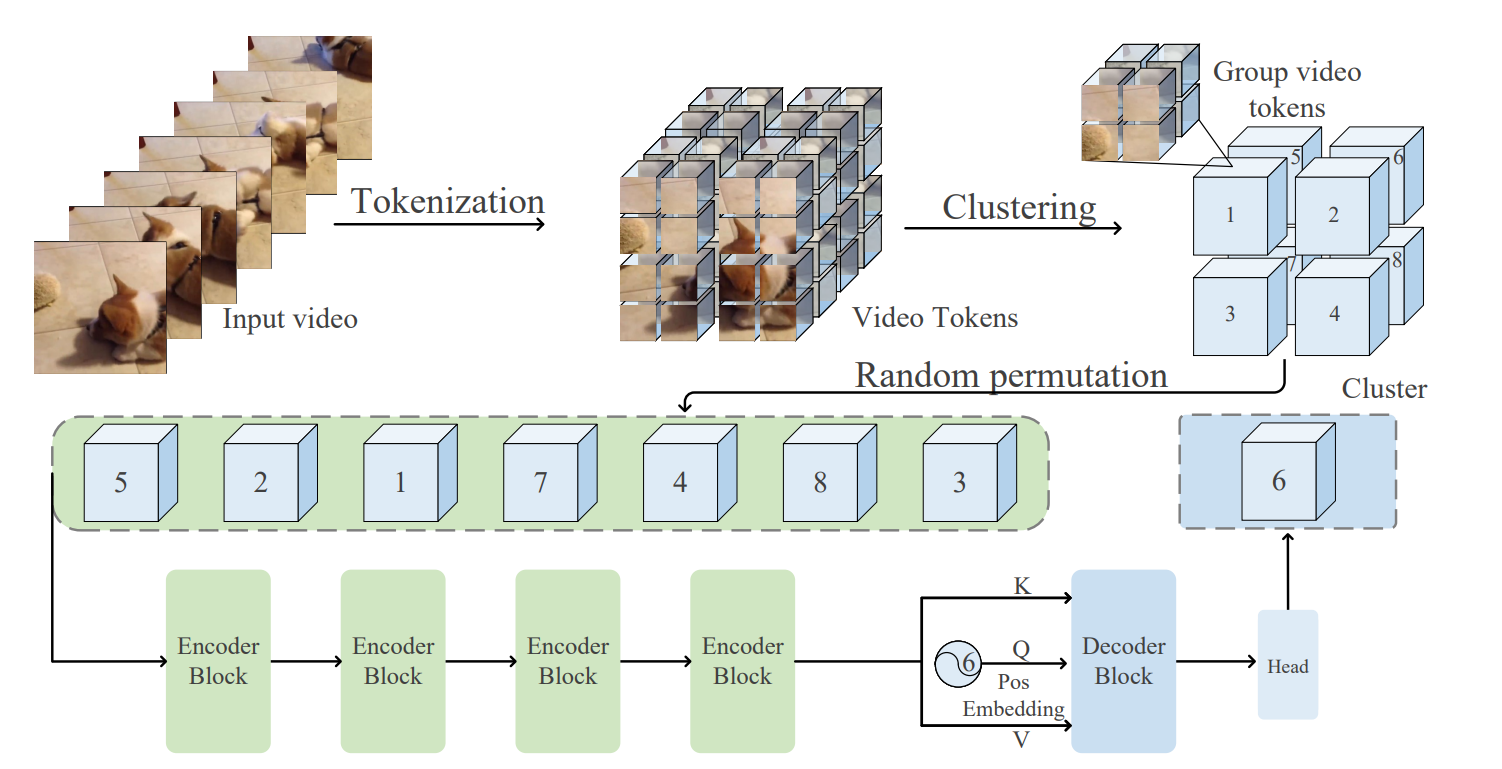 |
Sucheng Ren, Hongru Zhu, Chen Wei, Yijiang Li, Alan Yuille, Cihang Xie Transactions on Machine Learning Research (TMLR), 2025 [paper] [code] [bibtex] We use autoregressive pretraining for self-supervised video representation learning |
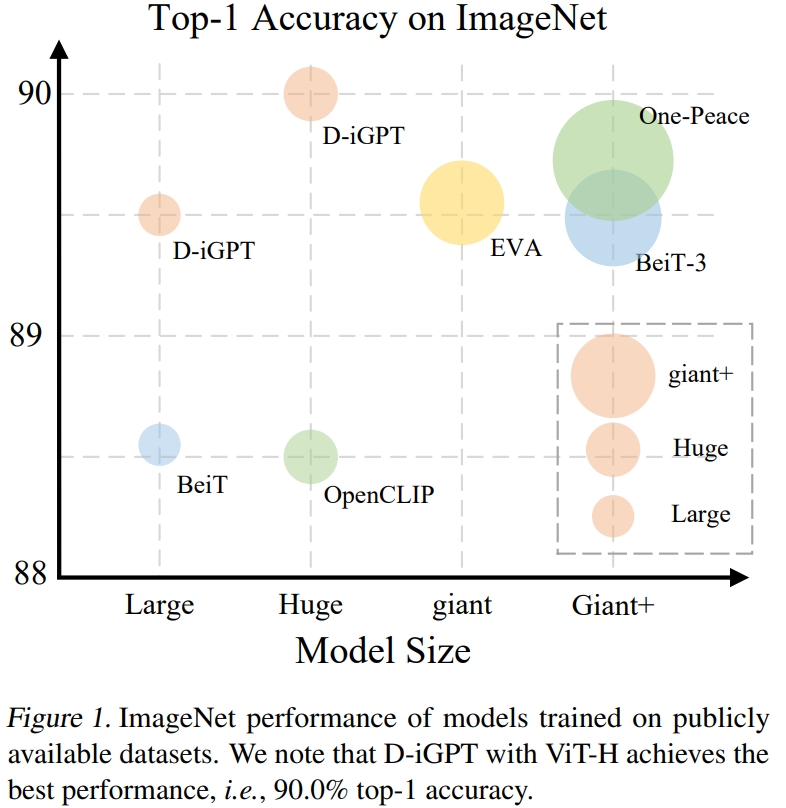 |
Sucheng Ren, Zeyu Wang, Hongru Zhu, Junfei Xiao, Alan Yuille, Cihang Xie International Conference on Machine Learning (ICML), (Oral), 2024 [paper] [code] [bibtex] We enhance image-GPT with semantic-rich supervision. |
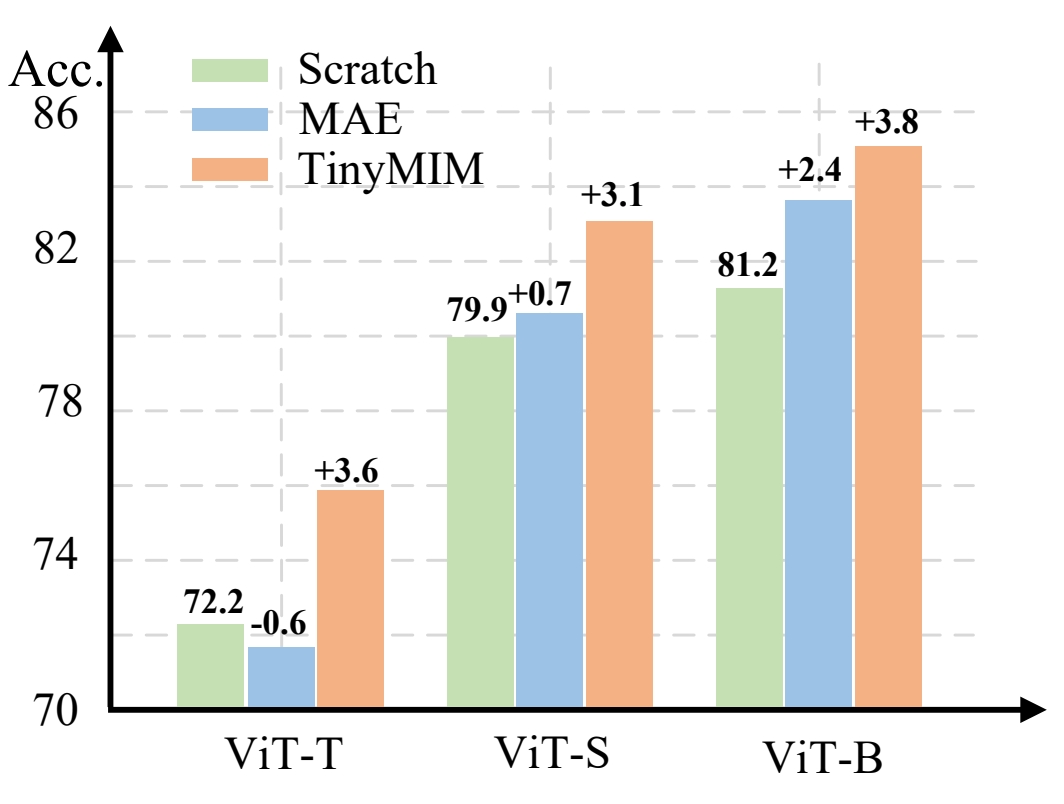 |
Sucheng Ren, Fangyun Wei, Zheng Zhang, Han Hu IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 [paper] [code] [bibtex] We explore distillation techniques to transfer the success of large MIM-based pre-trained models to smaller ones. |
 |
Sucheng Ren, Daquan Zhou, Shengfeng He, Jiashi Feng, Xinchao Wang IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (Oral), 2022 [paper] [code] [bibtex] Integrating the capability of capturing multiscale objects in each attention layer by adaptively merging tokens. |
 |
Sucheng Ren, Xingyi Yang, Songhua Liu, Xinchao Wang International Conference on Computer Vision (ICCV), 2023 [paper] [code] [bibtex] Integrating the capability of capturing multiscale objects in each attention layer by adaptively merging tokens. |
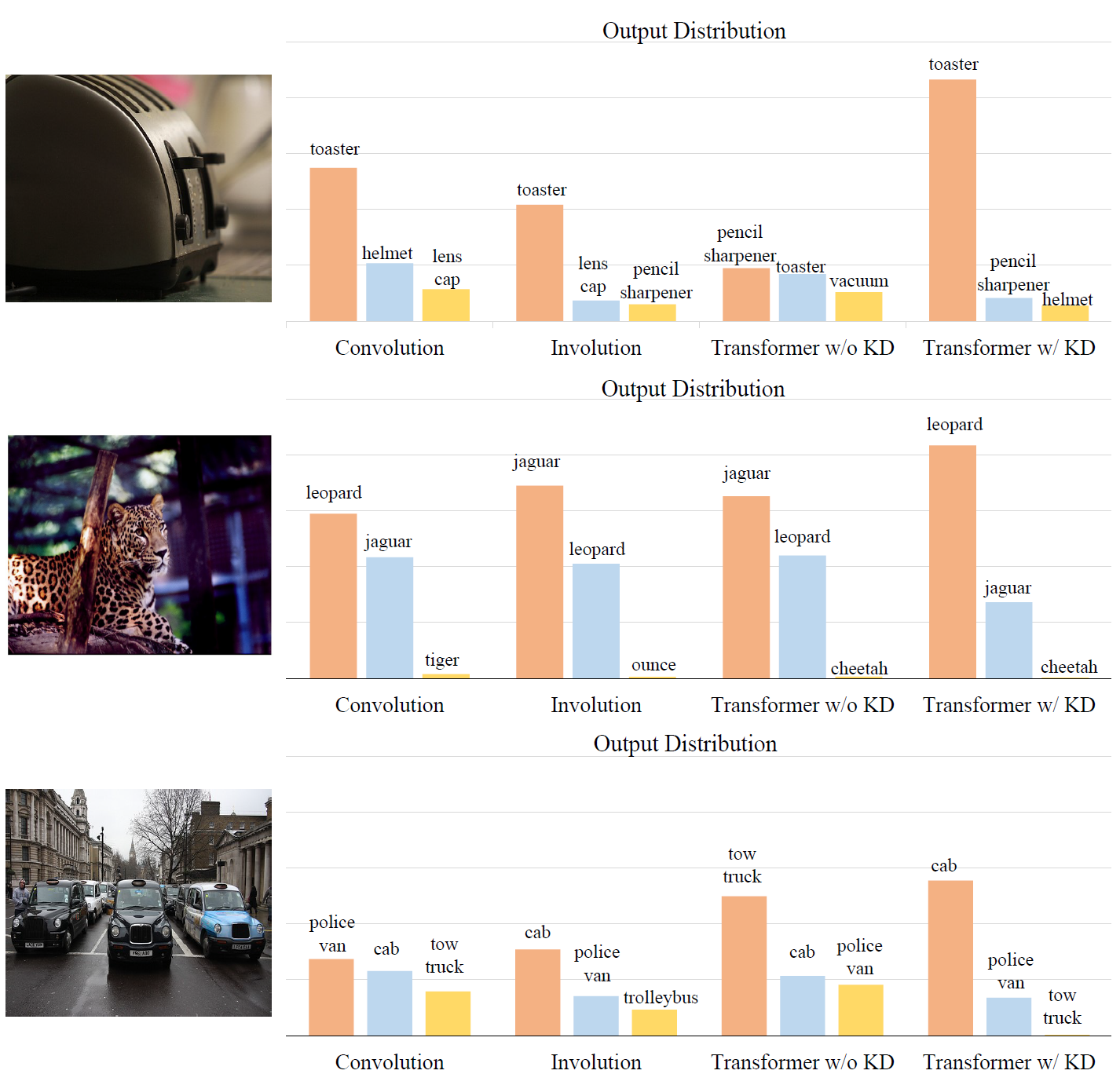 |
Sucheng Ren, Zhengqi Gao, Tianyu Hua, Zihui Xue, Yonglong Tian, Shengfeng He, Hang Zhao IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [paper] [code] [bibtex] The first work delves into the influence of models inductive biases in knowledge distillation |
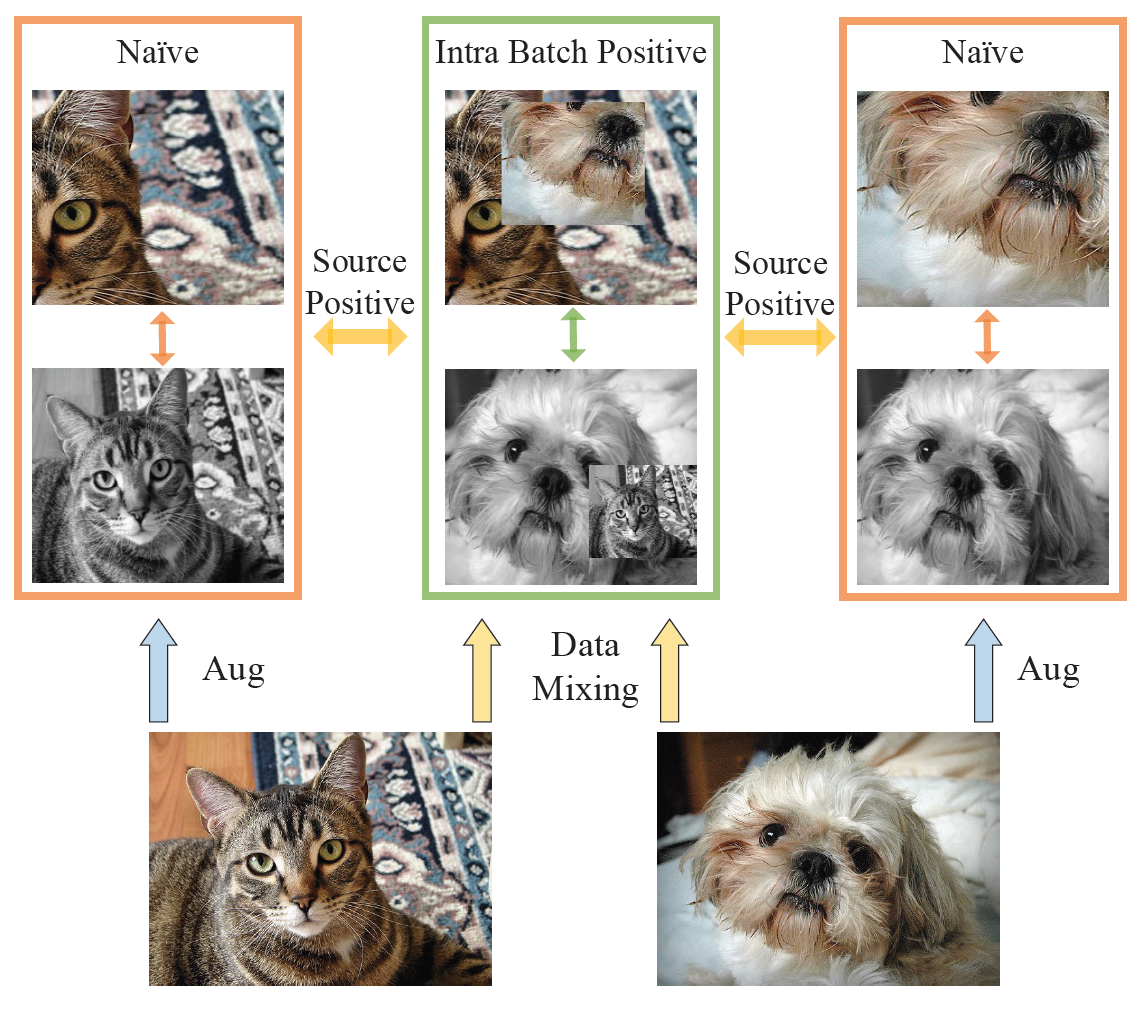 |
Sucheng Ren, Huiyu Wang, Zhengqi Gao, Shengfeng He, Alan Yuille, Yuyin Zhou, Cihang Xie IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 [paper] [bibtex] A generic training strategy in data mixing that can improve the self-supervised representation learning of both CNNs and ViTs |
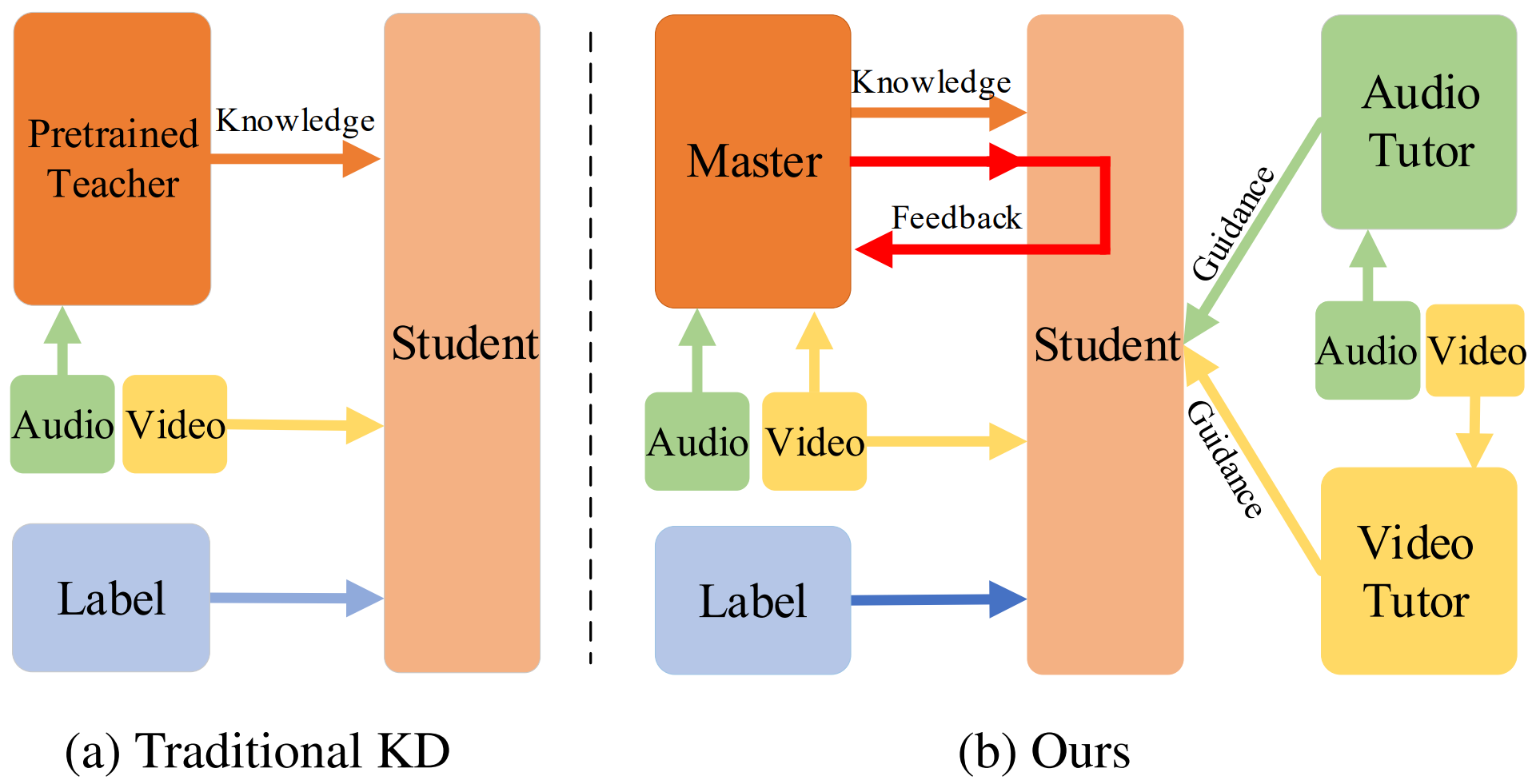 |
Sucheng Ren, Yong Du, Jianming Lv, Guoqiang Han, and Shengfeng He IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [paper] [bibtex] Training a master to learn how to teach a better student. |
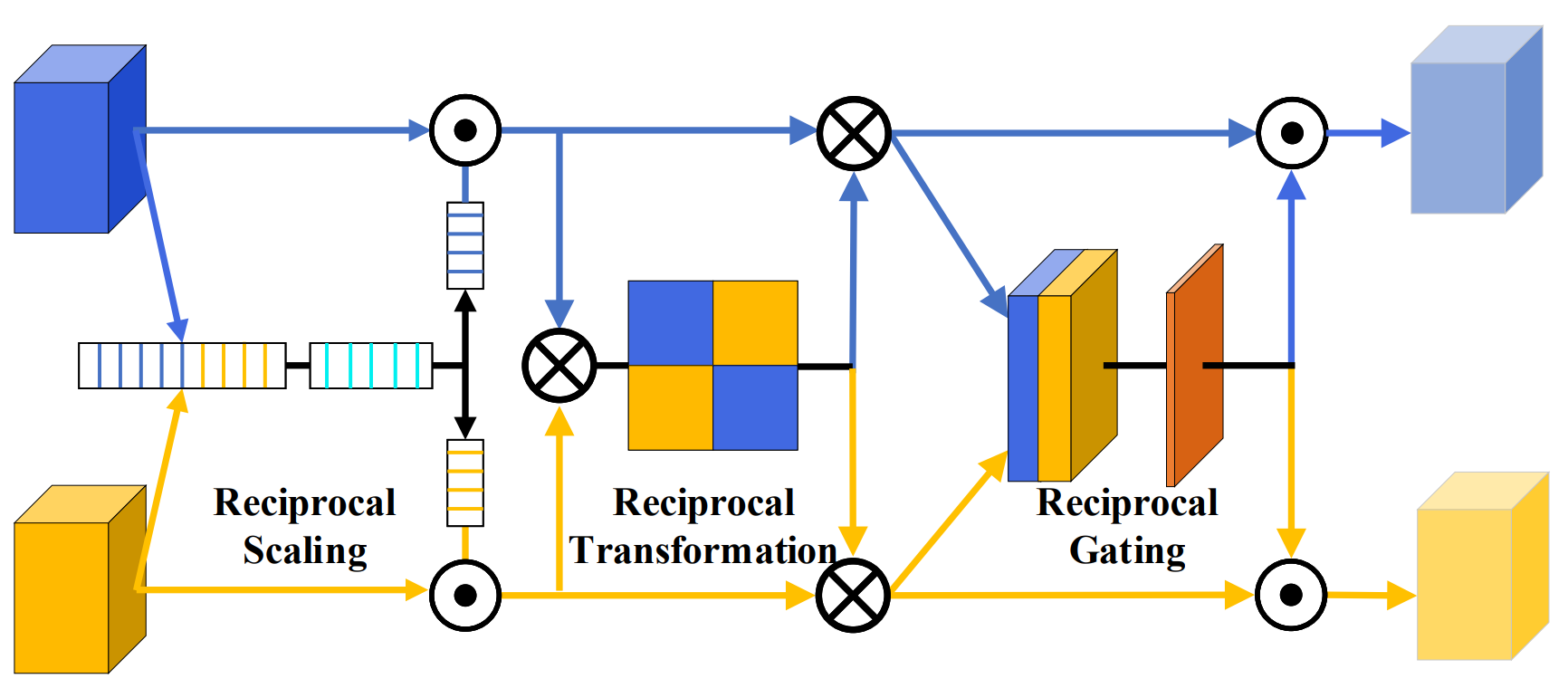 |
Sucheng Ren, Wenxi Liu, Yongtuo Liu, Haoxin Chen, Guoqiang Han and Shengfeng He IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [paper] [bibtex] [code] Jointly learning salient objects, moving objects, recurring objects for Unsupervised Video Object Segmentation. |
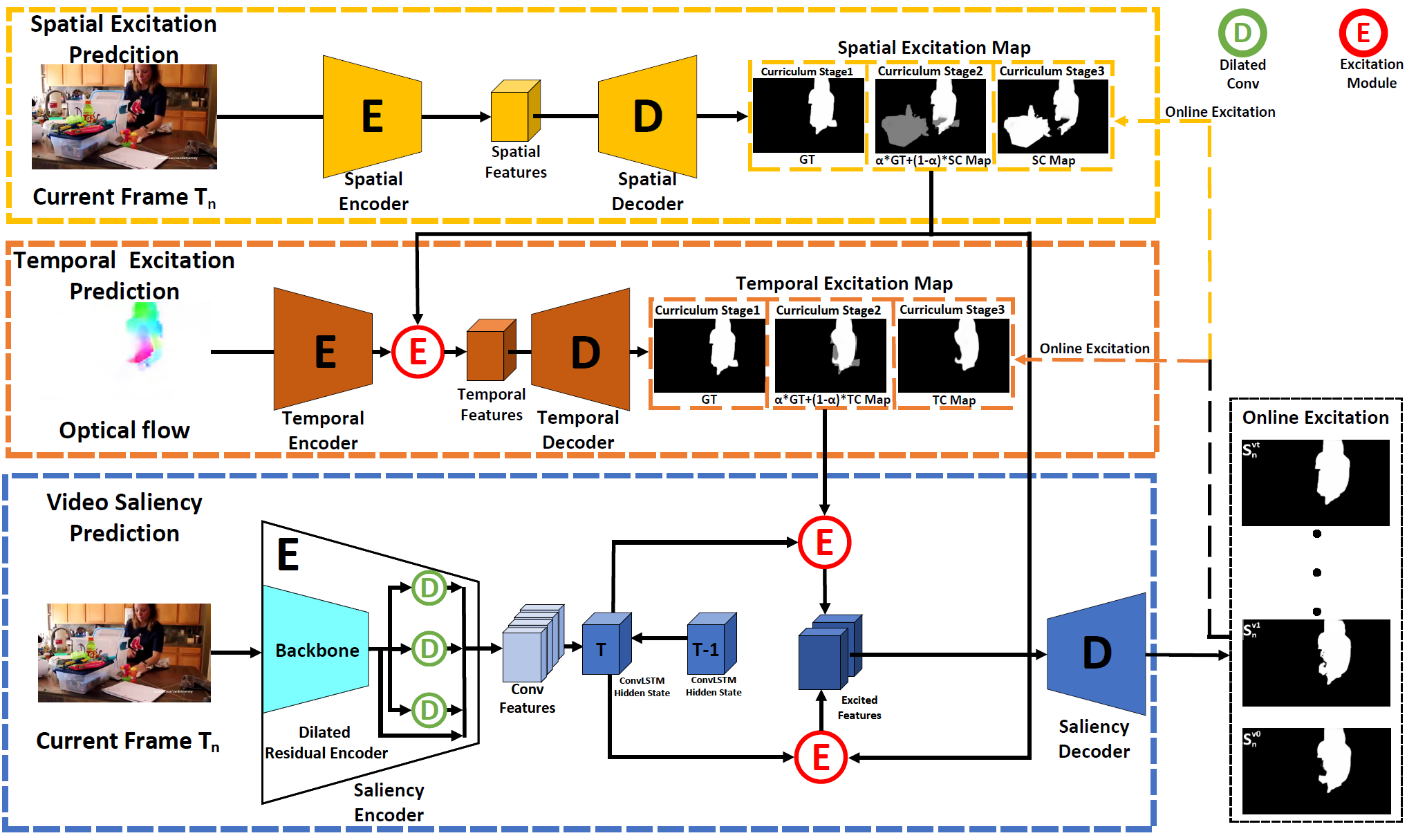 |
Sucheng Ren, Chu Han, Xin Yang, Guoqiang Han and Shengfeng He European Conference on Computer Vision (ECCV), 2020 (Spotlight, Acceptance Rate 5.0%) [paper] [bibtex]
|